




Get the latest

ESG REPORT
Fortified cyber readiness and resilience
Discover a new, validated approach to cyber recovery testing.

SOLUTION BRIEF
Clean recovery to an on-demand cleanroom
Unlock the ultimate safe haven in a chaotic, hybrid world.

IDC MARKET NOTE
Unlocking cyber resilience with recovery
Strengthen the “identify” and “recover” pillars of NIST framework for innovative security.
The world has changed.
Ransomware is everywhere:
99%
of ransomware tampers with security and backup infrastructure.
Breaches are becoming the norm:
66%
of organizations surveyed were breached in 2023.
Average time to recover is devastating:
24 days
is the average reported time to recover from a cyber attack.
Sources: Microsoft Digital Defense Report 2022; Verizon, 2024 Data Breach Investigations Report; U.S.
Government Accountability Office (GAO)
Government Accountability Office (GAO)
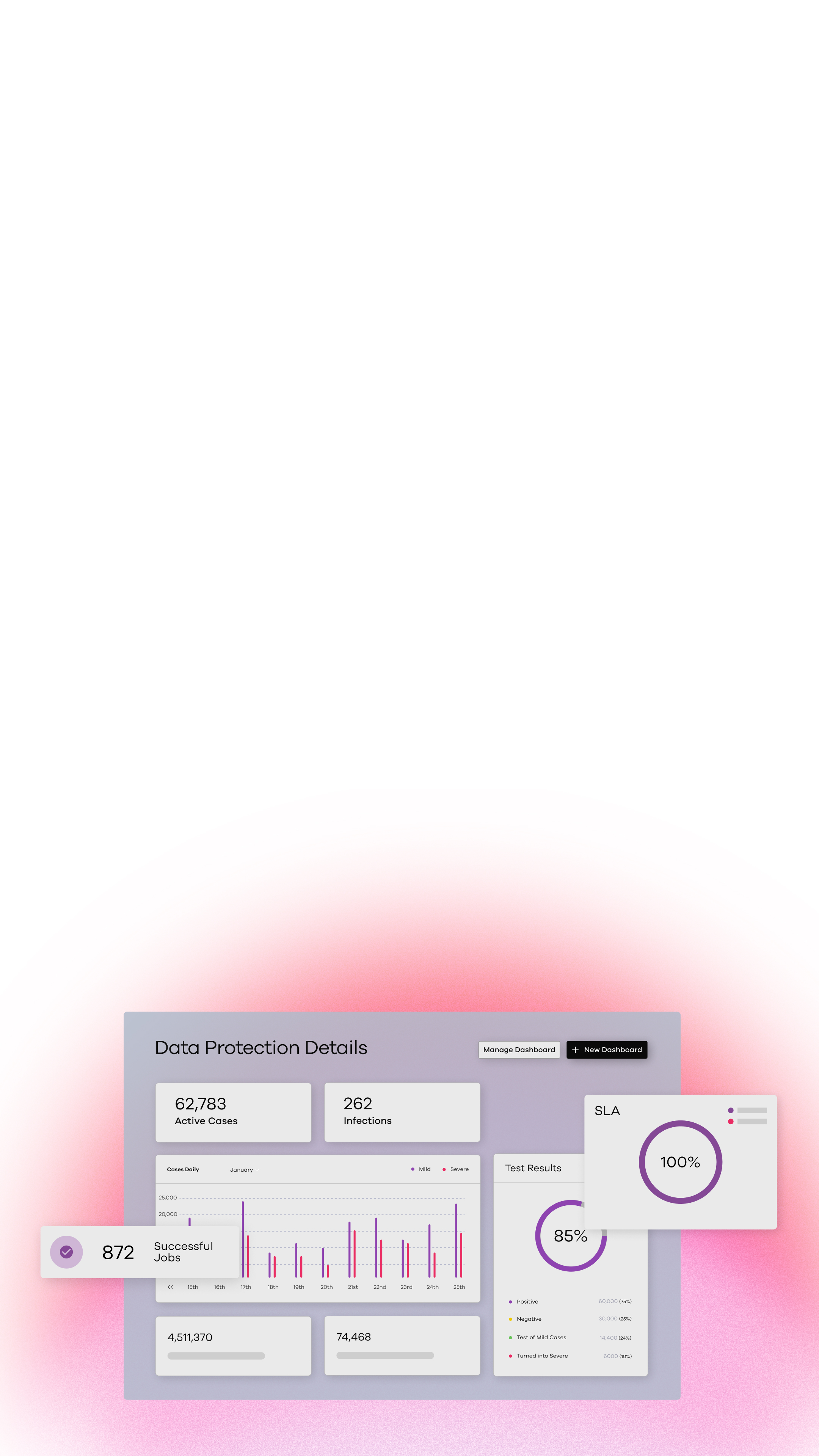
COMMVAULT CLEANROOM RECOVERY
Put your resilience to the test.
Commvault Cloud Cleanroom Recovery is the only offering that makes reliable cyber recovery testing and readiness possible for any enterprise.
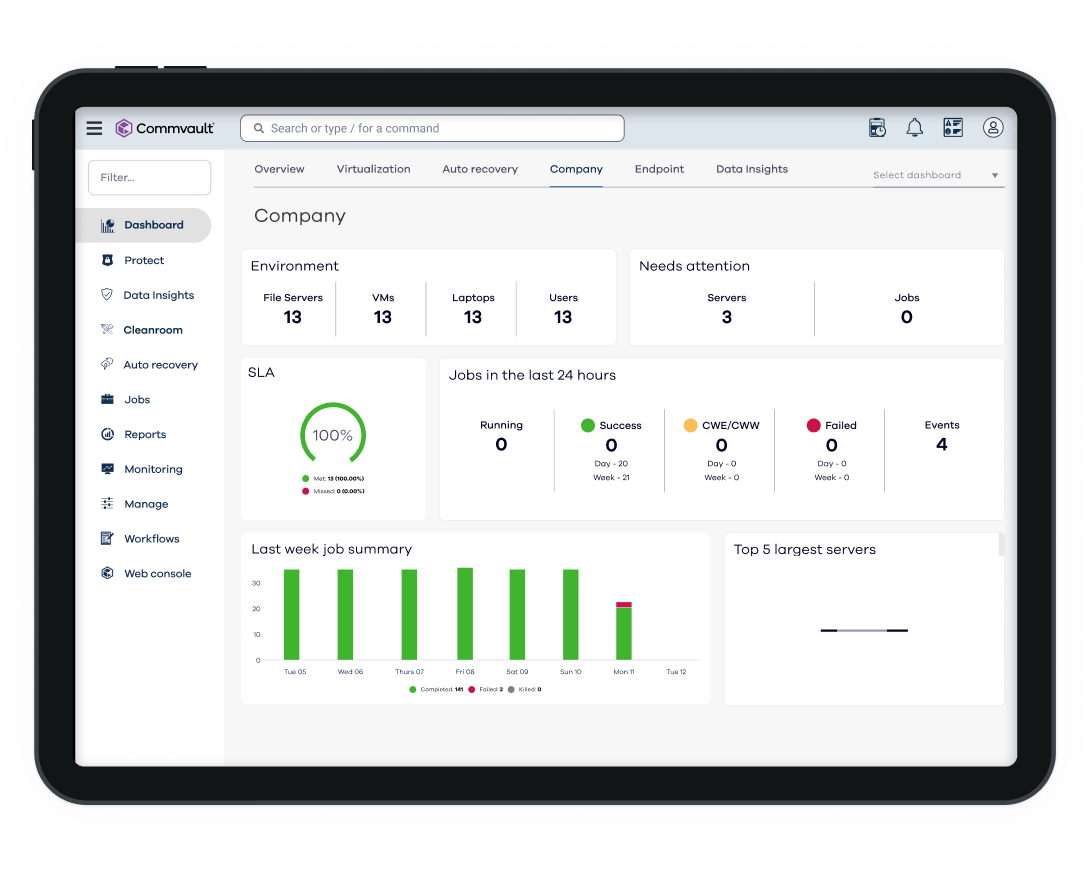
SIMPLE
Readiness within reach, for any organization.
Any enterprise can have cyber recovery readiness and resilience without the cost of dark site locations and complex infrastructure proliferation.
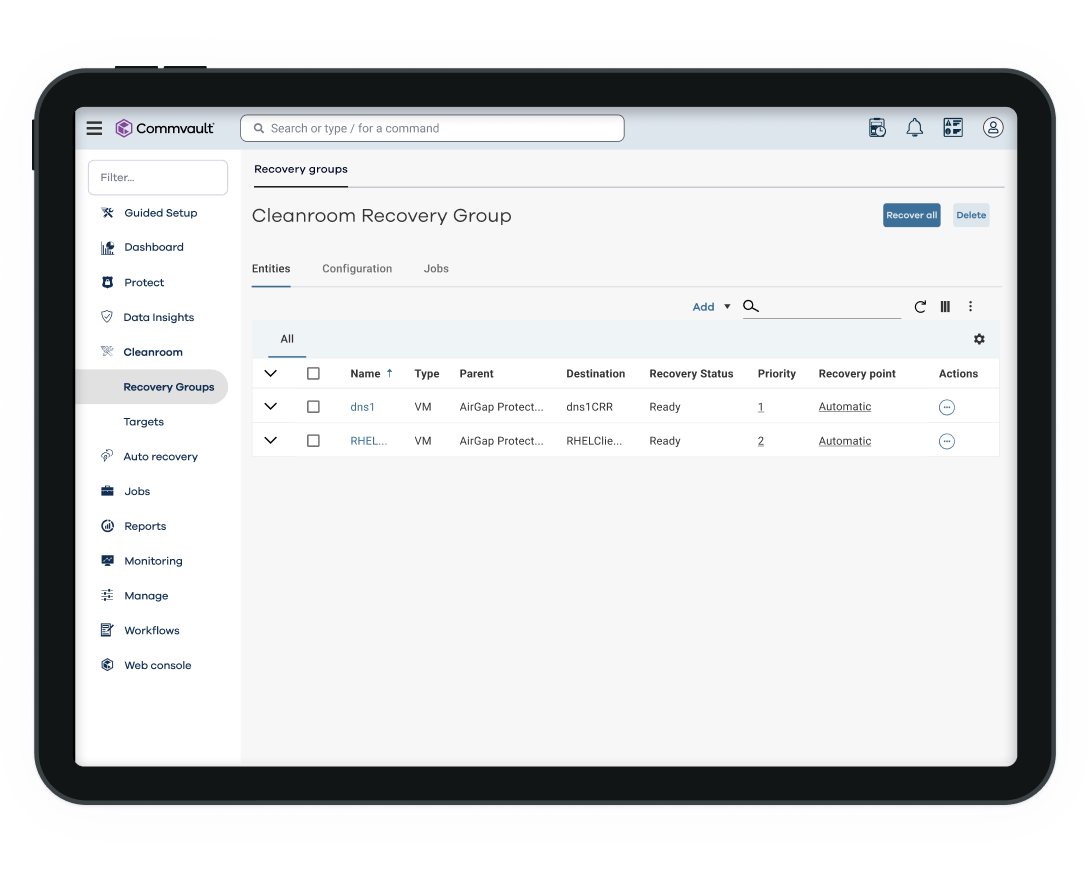
SECURE
Clean recovery. Clean locations. Isolated testing.
Built-in integrations with MSFT Defender for threat scanning and Palo Alto XSOAR for forensics.
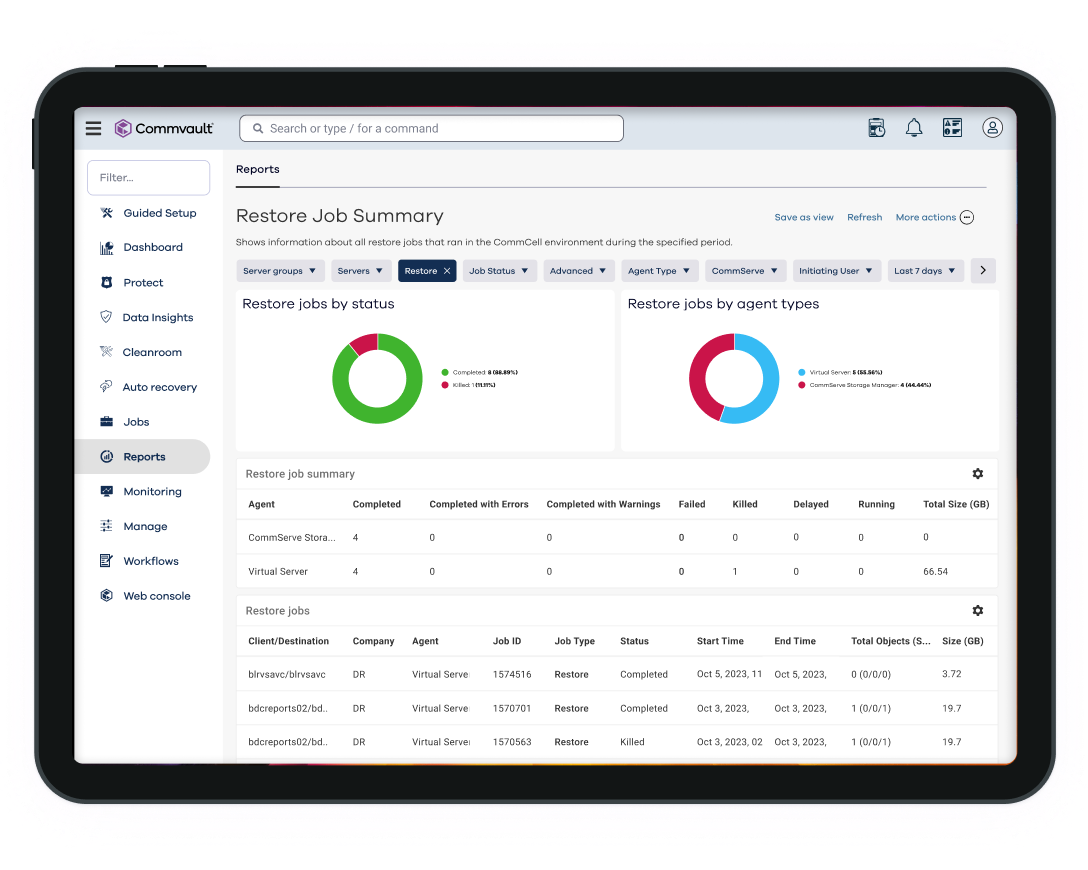
Intelligent
AI-enhanced for reliable testing.
Intelligent and automated Cleanpoint™ Validation includes orchestration and post-validation for more efficient and reliable recovery.

REFERENCES
Everyone is talking about Cleanroom Recovery
“Commvault Cloud Cleanroom Recovery not only enables organizations to test their recovery plans often, but know that if they’re hit, they can be resilient.”
“Having this sense of security is so important in the ransomware era.”
“Cleanroom Recovery is a game-changer for Commvault Cloud. It enables comprehensive testing, and retesting, on the fly which is something that traditional cleanroom solutions don’t provide. It also is designed to help organizations to rapidly recover from a cyber incident. The level of confidence and security this innovative solution can provide is invaluable.”

“We are excited about the advent of Cleanroom technology in our services. This approach allows us to test our recoverability and create a meticulous checklist for system recovery, utilizing a fully segmented Cleanroom to rapidly restore critical infrastructure.”
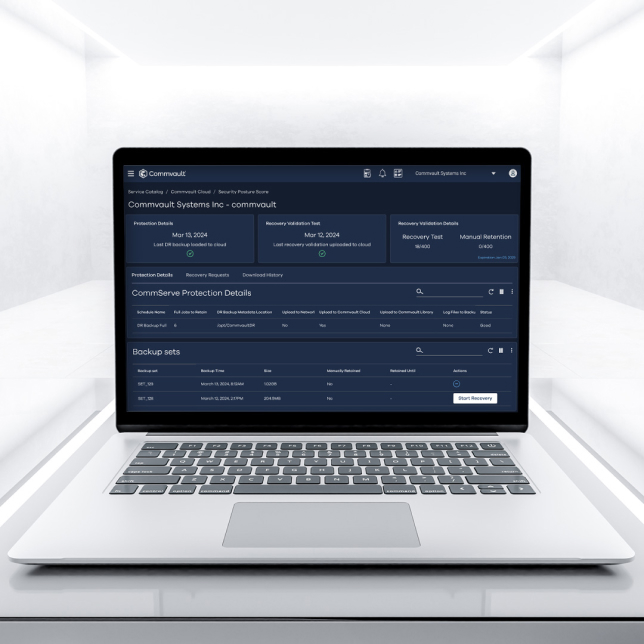
Your Platform for Total Cyber Resilience
We believe our platform is the first to offer true cloud cyber resiliency, built for AI, hybrid, chaos, and scale.
our reach
Supporting more than 100,000 companies






STRATEGIC PARTNERS & INTEGRATIONS
Unlock the full potential of true cyber resilience
Perform a clean and easy restore in a new uncontaminated Microsoft Azure tenant.
Provides advanced security measures, data intelligence, and threat detection capabilities.
Reduce incident response time with automated orchestration and combined insights.
Ready to take the next step?
Experience the platform that delivers true cloud cyber resilience